
دنیایی که در آن زندگی میکنیم به لطف فناوری به سرعت در حال تغییر است. این روزها بیش از هر زمان دیگری هوش مصنوعی برای ما مهم شده و در حال دست و پنجه نرم کردن برای شناخت بهتر آن هستیم. در محتوای «هوش مصنوعی چیست؟» با مفهوم و انواع آن آشنا شدیم و متوجه شدیم که پیشرفت های هوش مصنوعی بالاتر از حد تصور ما بوده، طوریکه داستانهای علمی تخیلی را به واقعیت تبدیل کرده است. شناخت بهتر هوش مصنوعی به ما کمک می کند تا زندگی بهتری داشته باشیم؛ برای شناخت بهتر هوش مصنوعی بهتر است ابتدا، با مفاهیم و اصطلاحات مهم دنیای فناوری آشنا شویم. یکی از اصطلاحات مهمی که در دنیای فناوری موج سواری می کند، یادگیری ماشین است. در این مقاله قصد داریم، به این سوال که ” یادگیری ماشین چیست؟ ” پاسخ دهیم تا به درک درستی از آن برسیم. زیرا درک مفهوم ماشین لرنینگ، روشهای آن و کاربردهای عملی آن برای افرادی که در حوزه فناوری فعالیت میکنند، اهمیت دارد.
فهرست عناوین
- یادگیری ماشین چیست؟
- تعریف یادگیری ماشین به زبان ساده
- چرا یادگیری ماشین اهمیت دارد؟
- یادگیری ماشین چگونه کار میکند؟
- الگوریتم های یادگیری ماشین
- مراحل یادگیری ماشین
- چه زمانی باید از یادگیری ماشین استفاده کرد؟
- تفاوت داده کاوی و ماشین لرنینگ
- تاریخچه ماشین لرنینگ
- تفاوت بین هوش مصنوعی، ماشین لرنینگ و یادگیری عمیق
- بهترین زبان برنامه نویسی برای یادگیری ماشین
- کاربردهای یادگیری ماشین
- مزایا و معایب یادگیری ماشین
- آینده یادگیری ماشین چگونه خواهد بود؟
یادگیری ماشین چیست؟
یادگیری ماشین یا machine learning زیر مجموعهای از هوش مصنوعی است و همان طور که هوش مصنوعی برای یادگیری به یکسری داده نیاز دارد تا بتواند تصمیم گیری کند، یادگیری ماشین هم از یکسری الگوریتم استفاده میکند تا به ماشینها کمک کند، عملکردشان را در طول زمان، با یادگیری از دادهها، بدون برنامه ریزی بهبود بخشند. برای درک بهتر، ماشین را مانند یک کودک نوپا در نظر بگیرید، در ابتدا، لازم است که یکسری راهنمایی و آموزش به او داده شود تا بعد او بتواند بعد از چندین بار تلاش کردن، یاد بگیرد و به طور مستقل کار را انجام دهد. نحوه کار یادگیری ماشین هم دقیقا همینطور است. ابتدا یکسری آموزش به ماشین داده می شود تا بعدا بتواند پیش بینی یا تصمیم گیری کند.
یادگیری ماشین را در همه جا میتوان دید، از این الگوریتمهای یادگیری در نتفلیکس، آمازون و استپاتیفای و همچنین در دستیارهای صوتی مانند سیری و اکسا استفاده میشود. نمونهی دیگری از یادگیری ماشین را میتوان در تشخیص تقلب در بانکداری دید. بهطور کلی ماشین لرنینگ بهطور گسترده در بخشهای مختلفی دیده میشود و باعث بهبود تجربه کاربر و کارآمد کردن فرآیندها میشود.
تعریف یادگیری ماشین به زبان ساده
اگر بخواهیم تعریف سادهتری از ماشین لرنینگ داشته باشیم، باید بگوییم که یادگیری ماشین، یعنی ماشینها و کامپیوترها را وادار کنیم مانند انسان یاد بگیرند و عمل کنند، اما سریعتر و دقیقتر از انسان. تقلید از رفتار انسان و شبیه سازی ذهن انسان کاری است که در ماشین لرنینگ انجام میشود. از آن جایی که انسان توان محاسبه ی دقیق حجم زیادی از داده را ندارد و باید زمان زیادی برای این کار اختصاص دهد، استفاده از ماشین لرنینگ مثمر ثمر خواهد بود؛ چرا که هم کار با سرعت بالاتری انجام می شود هم احتمال خطا کمتر می شود. ماشین باید توانایی این را داشته باشد تا از خودش یاد بگیرد. اما این کار چه سودی برای ما دارد؟
فرض کنیم در خط تولید یک کارخانه یک نیروی انسانی قرار بگیرد. کیفیت کار نهایی به عوامل مختلفی بستگی دارد. مثلا ممکن است با گذشت زمان نیرو خسته شود، مریض شود و یا از ادامه کار منصرف شود. اما اگر به یک ماشین آموزش داده شود که کارها را بر چه اساسی انجام دهد و متناسب با آن شروع به کار کند، بهتر از انسان می تواند کار را انجام دهد؛ چرا که در این شرایط دیگر احتمال مریضی و خستگی وجود ندارد.
 ماشین بدون احتمال مریضی و خستگی، بهتر از انسان در خط تولید عمل میکند.
ماشین بدون احتمال مریضی و خستگی، بهتر از انسان در خط تولید عمل میکند. در این جا فقط لازم است ماشین به چند سوال پاسخ دهد، مثل این که کار تولید تا چه زمانی ادامه پیدا می کند و یا تا چه زمانی قرار است، کار را ادامه دهد. این دقیقا کاری است که ماشین لرنینگ انجام می دهد، یادگیری از خود و بهبود رفتار!
یک مثال دیگر، فیلتر اسپم ایمیل را در نظر بگیرید. بهنظر شما چگونه ارائهدهنده ایمیل متوجه میشود که کدام ایمیل هرزنامه است و کدام ایمیل نیست؟ از یادگیری ماشین برای این مدل تشخیص استفاده میشود. فیلتر هرزنامه با هزاران ایمیل که شامل ایمیل های عادی و هرزنامه است، آموزش میبیند، یاد میگیرد و چگونه بین دو ایمیل تمایز قائل شود و با هر بار پیشبینی درست بهتر میشود، تا بتواند تشخیص دهد کدام ایمیل هرزنامه هستند کدام ایمیل نه!
چرا یادگیری ماشین اهمیت دارد؟
یادگیری ماشین نحوه تعامل ما با فناوری را تغییر میدهد، اهمیت درک یادگیری ماشین فقط مخصوص علاقهمندان به فناوری یا دانشمندان نیست. ماشین لرنینگ در حوزهها و صنایع مختلفی به کار برده میشود. درک یادگیری ماشین از آنجایی ضرورت دارد که یادگیری ماشین در زندگی روزمره ما فراگیر شده است.
در حوزههای مختلفی مانند مراقبتهای بهداشتی، الگوریتم یادگیری ماشین میتواند شیوع بیماریها را پیشبینی کند و به کاهش اثرات آن کمک کند.در بخش مالی این الگوریتمها میتوانند بهتر ارزیابی کنند و ریسک و کشف تقلب را آسان کنند. به شرکتها یک دید از رفتار مشتری و الگوهای عملیاتی تجاری میدهد و برای آنها تجربیات مشتری را شخصی سازی میکند و باعث رشد کسب و کار و حفظ مشتری میشود.
در حوزههای مختلفی مانند مراقبتهای بهداشتی، الگوریتم یادگیری ماشین میتواند شیوع بیماریها را پیشبینی کند و به کاهش اثرات آن کمک کند.در بخش مالی این الگوریتمها میتوانند بهتر ارزیابی کنند و ریسک و کشف تقلب را آسان کنند. به شرکتها یک دید از رفتار مشتری و الگوهای عملیاتی تجاری میدهد و برای آنها تجربیات مشتری را شخصی سازی میکند و باعث رشد کسب و کار و حفظ مشتری میشود.
یادگیری ماشین برای همه کسب و کارها ضروری است چون در تمام زندگی فراگیر شده باردیگر میخواهیم از منظر دیگری به پرسش «چرا یادگیری ماشین اهمیت دارد؟» پاسخ دهیم. پشتیبانی از توسعه محصولات جدید از دیگر مزایای درک مفهوم یادگیری ماشین است. امروزه شرکتهای زیادی هستند که مانند فیسبوک، گوگل و اوبر یادگیری ماشین را به بخش مرکزی عملیات خود تبدیل کردهاند. در واقع در چنین شرایطی یادگیری ماشین به یک وجه تمایز رقابتی برای شرکتها تبدیل شده است.
از طرف دیگر، میتوان از یادگیری ماشین برای موارد مختلفی استفاده کرد، از جمله:
- کاهش هزینهها
- کاهش خطرات
- بهبود کیفیت کلی زندگی از جمله محصولات و خدمات
- شناسایی نقضهای امنیت سایبری
دسترسی بیشتر به دادهها و قدرت محاسباتی موجب میشود که یادگیری ماشین هر روز فراگیرتر شود و به مرور با بسیاری از جنبههای زندگی انسان ادغام میشود.
یادگیری ماشین چگونه کار میکند؟
فرآیند یادگیری ماشین زمانی شروع میشود که دادههای آموزشی به الگوریتم وارد شوند. سپس نوبت به تجزیه و تحلیل داده میرسد و از این الگوریتمها برای یادگیری مکرر از داده، اصلاح بینش و تصمیمگیری استفاده میشود. نوع ورودی دادههای آموزشی روی الگوریتم تاثیر میگذارد و این مفهوم هر لحظه پوشش داده میشود.
فرآیند یادگیری ماشین با تجزیه و تحلیل بهبود پیدا میکند. درست برعکس الگوریتمهای سنتی که کاملا منطبق بر قانون هستند، این الگوریتمها خروجی را بر اساس دادههای جدید تنظیم میکنند. ورودیهای جدیدی که به الگوریتم یادگیری ماشین اضافه میشوند، مورد آزمایش قرار میگیرند تا مشخص شود، الگوریتم به درستی کار میکند یا خیر. سپس، پیشبینی و نتایج با هم مقایسه میشوند.
چنانچه پیشبینی و نتایج با هم مطابقت نداشته باشند، الگوریتم مجدد آموزش داده میشود، تا جاییکه دانشمند به نتیجه مطلوب برسد. این امر به الگوریتم یادگیری ماشین این امکان را میدهد که بهطور مداوم و به تنهایی یاد بگیرد، پاسخ بهینه تولید کند و بهتدریج در طول زمان عملکرد آن افزایش پیدا کند.
برای درک بهتر این فرآیند، یادگیری ماشین را مانند آموزش دوچرخه سواری به کودک تصور کنید. در روزهای اول کودک بارها میافتد و نمیتواند به خوبی تعادل را حفظ کند، به مرور با تمرین کردن سعی میکند تعادل پیدا کند. پس از تلاشهای بسیار بالاخره، کودک موفق میشود تعادل خود را حفظ کند و بدون افتادن دوچرخهسواری کند.
فرآیند یادگیری ماشین با ورود دادههای آموزشی، تجزیه و تحلیل و تصمیمگیری، همواره بهبود و پیشرفت میکند. به طور مشابه، الگوریتمهای یادگیری ماشین تکرار میشوند، از دادهها یاد میگیرند، پیشبینیها یا طبقهبندیهای خود را با هر پاس تنظیم دقیق میکنند. به طور کلی این الگوریتمها در طول زمان یاد میگیرند و بهبود پیدا میکنند.
لازم به ذکر است که یادگیری ماشین فقط به یک رویکرد محدود نمیشود و روشهای مختلفی برای یادگیری ماشین وجود دارد، از جمله یادگیری تحت نظارت، یادگیری بدون نظارت و یادگیری تقویتی که هرکدام کاربردهای متفاوتی دارند. برای مثال الگوریتم یادگیری نظارت شده برای پیشبینی قیمت مسکن، هرزنامه ایمیل و امتیازدهی اعتبار کاربرد دارد، الگوریتم یادگیری بدون نظارت برای خوشهبندی مشتریان در گروههای مختلف و… در ادامه هر یک از این روشها را توضیح خواهیم داد.

الگوریتم های یادگیری ماشین
از آنجایی که یادگیری ماشین پیچیده است، در 4 بخش اصلی طبقهبندی میشوند، یادگیری تحت نظارت، یادگیری بدون نظارت، یادگیری نیمه نظارتی و یادگیری تقویتی. میتوان گفت که هرکدام هدف و عمل خاصی دارند از اشکال مختلف داده استفاده میکنند. حدود 70 درصد از یادگیری ماشین متعلق به یادگیری تحت نظارت است، و بین 10 تا 20 درصد مربوط به یادگیری بدون نظارت است و مابقی توسط یادگیری نیمه نظارت و یادگیری تقویتی ارائه میشود.
یادگیری تحت نظارت یا یادگیری نظارت شده
یکی از روشهای رایج است که در آن ماشین بر روی یک مجموعه داده برچسبگذاری شده، آموزش داده میشود. درست مثل اینکه زیر نظر معلم یاد بگیرید. در اینجا ماشین از جفتهای ورودی- خروجی یاد میگیرد و آموزش میبیند تا بتواند پیشبینی کند. آموزش تا آنجایی ادامه پیدا میکند که مدل به سطح قابل قبولی از عملکرد برسد.
پس از دریافت آموزشهای کافی، سیستم میتواند برای هر داده، هدف جدیدی را مشخص کند. همچنین میتواند خروجیها را با هم مقایسه کند و اگر خطایی وجود داشت، آن خطاها را اصلاح کند.
سیستم میتواند هدف جدیدی را مشخص کند و اگر خطایی بود، اصلاحات انجام دهد. Trees، Support Machines Vector، Random Forests و Naive Bayes نمونه هایی از الگوریتم های یادگیری تحت نظارت هستند که برای طبقه بندی، رگرسیون و کارهای پیش بینی سری های زمانی قابل استفاده هستند. از این الگوریتم در حوزه های مختلف مانند مراقبت های بهداشتی، مالی، بازاریابی و پیش بینی ها استفاده می شود.
یادگیری بدون نظارت
همانطور که از نامش مشخص است، این مدل یادگیری بدون نظارت است. یکسری دادههای مورد نیاز بدون دستهبندی و برچسبگذاری شده به ماشین داده میشود، و هدف هم این است که ماشین بتواند الگوها و روابط بین دادهها را پیدا کند.
در این مدل سیستم خروجی مشخص نمیشود و ماشین فقط میتواند دادهها را پیدا کند و از روی دادههای برچسب زده نشده، ساختارهای پنهان را حدس بزند. معمولا از این روش برای خوشهبندی و تداعی استفاده میکنند.
الگوریتم های خوشه بندی مانند K-means، خوشه بندی سلسله مراتبی، DBSCAN، از تکنیک های رایج یادگیری بدون نظارت هستند. برای کارهایی مانند تقسیم بندی مشتری، تشخیص ناهنجاری و کاوش داده از این مدل الگوریتم استفاده می شود.
یادگیری نیمه نظارت
این الگوریتم مشابه با الگوریتم یادگیری تحت نظارت است ولی از داده های برچسب دار وبدون برچسب استفاده می کند. داده هایی که برچسب گذاری شدند، همان اطلاعاتی هستند که برچسب های معنی دار دارند تا بتوانند الگوریتم داده را درک کنند، در حالی که داده های بدون برچسب این اطلاعات را ندارند. با استفاده از این ترکیب، الگوریتمهای یادگیری ماشین قادر هستند تا داده های بدون برچسب را برچسب گذاری کنند.
یادگیری تقویتی
یکی دیگر از روشهای یادگیری، یادگیری تقویتی است و در آن یک عامل یاد میگیرد که چگونه با محیط خود تعامل کند، تصمیم بگیرد و خطاها و پاداشها را کشف کند. از ویژگیهای این روش، آزمایش کردن، جستوجوی خطا و پاداشهای تاخیری است. در این روش سیستم یک عمل خاص را انجام میدهد تا پاداش بگیرد یا جریمه شود. در یادگیری تقویتی این امکان به سیستم داده میشود که بتواند با گذشت زمان، عملکرد خود را به حداکثر برساند و تصمیماتی بگیرد که پاداش را به حداکثر برساند.

مراحل یادگیری ماشین
برای انتقال اطلاعات به ماشین ها لازم است مراحلی طی شود و این مراحل کمی سخت و غیر ممکن به نظر می رسد اما در واقع این طور نیست. انتقال اطلاعات 7 مرحله اصلی دارد که در ادامه بیان خواهیم کرد.
جمع آوری داده
در بالا به این موضوع اشاره کردیم که ماشین ها از طریق داده هایی که به آن ها می دهیم، آموزش می بینند. باید سعی کنیم داده های قابلی اعتمادی را جمع آوری کنیم تا مدل یادگیری ماشین بتواند الگوهای صحیح را پیدا کند. کیفیت و کمیت داده ها تعیین کننده این هستند که مدل ما چقدر دقیق است. اگر داده ها نادرست یا قدیمی باشند، خروجی اشتباه و نامرتبط خواهد بود. پس موقع انتخاب داده ها دقت کنید که از یک منبع قابل استفاده کنید.
آماده سازی دادهها
بعد از این که داده های خود را جمع آوری کردید، این کارها را انجام دهید:
- داده ها ها را به صورت تصادفی کنار هم قرار دهید. این موضوع کمک می کند تا مطمئن شوید، داده ها به طور یکنواخت پخش شده اند و ترتیب آن ها روی روند یادگیری تاثیر نمی گذارد.
- تمیز کردن داده ها به منظور جلوگیری از حذف داده های ناخواسته، مقادیر از دست رفته، برای تبدیل نوع داده، برای ردیف ها و ستون ها و مقادیر تکراری الزامی است. حتی شاید لازم باشد، مجموعه ای از داده ها را بازسازی کنید و ردیف، ستون یا شاخص ردیف و ستون را تغییر دهید.
- تجسم داده ها برای پی بردن به چگونگی ساختار آن ها لازم است و باید بتوانید رابطه بین متغیرهای مختلف درک کنید.
- در مرحله بعد باید داده های پاک شده را به دو مجموعه تقسیم کنید. یکی مجموعه آموزشی برای یادگیری مدل از آن و دیگری مجموعه تست برای بررسی دقت مدل پس از آموزش.
انتخاب مدل
در مرحله بعد باید بتوانیم یک مدل و آموزش را انتخاب کنیم و البته انتخاب مدل باید مرتبط با کار مورد نظر باشد. وظیفه مدل انتخابی انتخاب خروجی مناسب از روی الگوریتم های یادگیری ماشین است. چندین سال است که دانشمندان و مهندسان مدل های مختلفی را توسعه دادند که برای تشخیص گفتار، تشخیص تصویر، پیش بینی و …. مناسب است.
آموزش مدل
مهم ترین مرحله در یادگیری ماشین، آموزش است. در این مرحله باید داده ها را به مدل یادگیری ماشین منتقل کنیم تا الگوها را بیابد و پیش بینی کند. با انجام این کار، مدل از داده ها یاد می گیرد تا بتواند وظایف را انجام دهد. با گذشت زمان، مدل با آموزش می تواند پیش بینی را بهتر انجام دهد.
ارزیابی مدل
پس از آموزش مدل باید عملکرد آن را بررسی کنیم. در ارزیابی عملکرد باید از داده های نامرئی و دیده نشده استفاده کرد. داده های نامرئی همان مجموعه آزمایشی است که داده ها را قبلا به آن تقسیم کردیم. در این صورت دقت آزمایش و اندازه گیری بالاتر می رود. اگر آزمایش روی داده های قبلی انجام شود، اندازه گیری دقیقی به دست نمی آید.
تنظیم پارامتر
بعد از ایجاد و ارزیابی مدل باید بتوانیم دقت آن را به روش های مختلف بهبود بدهیم. برای انجام این کار باید یکسری پارامتر را در مدل تنظیم کنیم. پارامترها متغیر های مدل هستند که باید برنامه نویس برای اجرای الگوریتم مشخص کند. در یک مقدار خاص از پارامتر، دقت در بالاترین میزان قرار دارد.
پیشگویی
در این مرحله می توان از مدل بر روی داده های دیده نشده برای پیش بینی دقیق استفاده کرد.
چه زمانی باید از یادگیری ماشین استفاده کرد؟
زمانی که ایجاد الگوریتمهای خاص برای انسان امکان پذیر نیست یا که برای انجام یک کار پیچیده، مقدار زیادی داده و متغیر دارید ولی فرمول یا معادلهای برای آن وجود ندارد، از یادگیری ماشین استفاده میکنیم. دلیل این کار این است که داده های زیادی وجود دارد و تحلیل آن ها به طور دستی برای یک فرد امکان پذیر نیست و یا زمان زیادی از او می گیرد. با وجود داده های بزرگ که در حال حاضر وجود دارد، یادگیری ماشین به یک ضرورت تبدیل شده است.
تفاوت داده کاوی و ماشین لرنینگ
داده کاوی در سال 1930 با هدف پیدا کردن اطلاعات مفید از میان حجم عظیمی از داده های با حجم بزرگ یا کلان داده، معرفی شد. از این داده ها برای پیش بینی وظایف کسب و کارها و سازمان های مختلف استفاده می شود. معرفی ماشین لرنینگ به سال 1950 برمی گردد و از الگوریتم ها استفاده می کند و داده های خام کاربردی در آن ندارند.
این دو تکنیک یکسری شباهت ها دارند ولی تفاوت هایی هم بین آن ها به چشم می خورد. یکی از تفاوت های مهمی که بین داده کاوی و یادگیری ماشین وجود دارد، حضور انسان در انجام کارها است.
حضور انسان باعث تفاوت بین دو تکنیک شده است. مثلا در داده کاوی برای استخراج اطلاعات، انسان نقشی ندارد ولی در ماشین لرنینگ تا مرحله انتخاب و به کارگیری الگوریتم یادگیری ماشین، انسان حضور دارد. نتایجی از که ماشین لرنینگ به دست میآید در مقایسه با داده کاوی دقیق تر است.
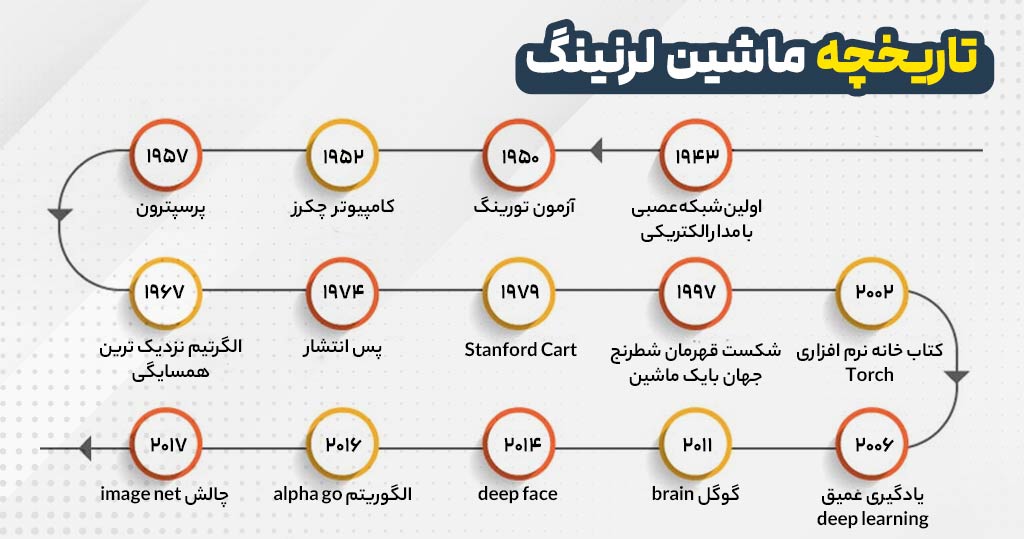
تاریخچه ماشین لرنینگ
یادگیری ماشین از زمان پیدایش کامپیوتر بخش جدایی ناپذیر از زندگی روزمره ما بوده و از ابتدای ظهور کامپیوترها تا الان شاهد حضور آن در زندگی هستیم. در ادامه برخی از مهمترین رویدادها را بررسی خواهیم کرد.
1943: اولین شبکه عصبی با مدار الکتریکی
در سال 1943 اولین شبکه خنثی با مدار الکتریکی توسط وارن مک کالوخ و والتر پیتس ایجاد شد. هدف از ایجاد شبکه حل مشکلی بود که جان فون نویمان و دیگر افراد آن را مطرح کرده بودند: چگونه می توان کامپیوترها را برای برقراری ارتباط با یکدیگر ساخت؟
این مدل اولیه امکان برقراری ارتباط بین دو کامپیوتر را بدون تعامل انسان، نشان داد. این رویداد راه را برای توسعه یادگیری ماشین هموار کرد.
1950: آزمون تورینگ
تست تورینگ یک تست هوش مصنوعی است که توسط آلن تورینگ ابداع شد. با استفاده از این تست میتوان تعیین کرد که آیا یک ماشین میتواند مانند یک انسان عمل کند؟ یا توانایی عاطفی را نشان دهد؟
تلاشهای زیادی برای ایجاد یک هوش مصنوعی انجام شده که بتواند تست تورینگ را پشت سر بگذراند، اما هنوز ماشینی نتوانسته این کار را باموفیت انجام دهد. البته تست تورینگ مورد انتقاد قرار گرفته و علت آن هم این است که بهجای اثبات هوش واقعی یک ماشین، میزان تقلید یک ماشین از انسان اندازهگیری میشود.
1952: کامپیوتر چکرز
آرتور ساموئل یک برنامه کامپیوتری برای بازی چکرز ایجاد کرد. در این برنامه آرتور از تکنیک هرس آلفا بتا استفاده کرد و از آن برای سنجش سانس برنده شدن در بازی استفاده کرد. علاوه براین ساموئل الگوریتم مینیمکس را هم توسعه داد و از آن برای به حداقل رساندن ضرر در بازیها استفاده کرد.
1957: پرسپترون
فرانک روزنبلات اولین شبکه عصبی را برای کامپیوترها اختراع کرد. پرسپترون یکی از اولین الگوریتم هایی بود که از شبکه های عصبی مصنوعی استفاده کرد و به طور گسترده در یادگیری ماشین استفاده شد. Perceptron با هدف بهبود دقت پیشبینیهای کامپیوتری طراحی شد تا بهوسیله آن کامپیوترها بهتر بتوانند از دادهها برای یادگیری استفاده کنند.
1967: الگوریتم نزدیکترین همسایگی
توسعه این الگوریتم با هدف شناسایی خودکار الگوها در مجموعه داده های بزرگ شکل گرفت تا بتواند، شباهت بین دو مورد را بیابد و تعیین کند که کدام یک به الگوی موجود نزدیکتر است. از این روش میتوان برای پیدا کردن روابط بین دادهها یا پیشبینی رویدادهای آینده مطابق با رویدادهای گذشته استفاده کرد.
1974: پس انتشار
طراحی پس انتشار یا Backpropagation برای کمک به شبکههای عصبی طراحی شد تا بتوانند از آن در یادگیری نحوه تشخیص الگوها استفاده کنند. هدف از این طرح بهبود دقت مدل با تنظیم وزن آن است تا بتواند خروجیها را با دقت بالاتری پیشبینی کند.
1979: Stanford Cart
دانشجویان دانشگاه کالیفرنیا یک ربات کنترل از راه دور ساختند که خودش میتوانست بدون دخالت انسان و برخورد کردن به اشیا در فضا حرکت کند.
ظهور یادگیری ماشین در قرن 21 نتیجه قانون مور و رشد تصاعدی آن است. زمانی که قدرت محاسباتی مقرون به صرفهتر شد، آموزش الگوریتمهای هوش مصنوعی با استفاده از دادههای بیشتر امکانپذیر شد که منجر به افزایش دقت و کارایی این الگوریتمها شد.
1997: شکست قهرمان شطرنج جهان با یک ماشین
Deep Blue ابر کامپیوتر شرکت IBM بود که استاد بزرگ شطرنج را در یک مسابقه شکست داد و این ماجرا موجب نگرانی شدید انسان در جامعه شطرنج شد. این شکست یک رویداد بزرگ تلقی شد چرا که انسانها فهمیدند هوش مصنوعی میتواند در کارهای پیچیده بر انسان پیروز شود.
2002: کتابخانه نرمافزاری Torch
Torch یک کتابخانه نرمافزاری است که از آن برای یادگیری ماشین و علوم داده استفاده میکنند. این کتابخانه اولین پلتفرم یادگیری ماشین رایگان در مقیاس بزرگ است و بهعنوان یک جایگزین برای سایر کتابخانهها بود. در حال حاضر، این کتابخانه یکی از کتابخانههای محبوب برای یادگیری ماشین است.
2006: یادگیری عمیق deep learning
2011: گوگل brain
2014: deep face
2016: الگوریتم Alpha Go
2017: چالش ImageNet

تفاوت بین هوش مصنوعی، ماشین لرنینگ و یادگیری عمیق
هوش مصنوعی و ماشین لرنینگ به جای یک دیگر به کار برده می شوند، اما بین آن ها تفاوت هایی وجود دارد و در واقع یادگیری ماشین و یادگیری عمیق زیر مجموعه ای از هوش مصنوعی هستند.
خیلی ساده میتوان تفاوت بین آن ها را بیان کرد؛ هدف هوش مصنوعی شبیه سازی هوش انسانی است در حالی که ماشین لرنینگ با استفاده از الگوریتم ها یاد می گیرد و در طول زمان عملکرد خود را بهبود می بخشد. هر نرم افزار یارانه ای، یک هوش مصنوعی تلقی می شود و از رفتارهای انسان تقلید می کند تا بتواند کارهایی را انجام دهد که به استدلال انسانی نیاز دارد. در صورتی که، یادگیری ماشین زیر مجموعه ای از هوش مصنوعی است و به سیستم اجازه می دهد که بر اساس داده ها، بدون برنامه ریزی پیش بینی کند و تصمیم بگیرد. تفاوت اصلی بین هوش مصنوعی و ماشین لرنینگ در توانایی آن ها برای یادگیری و سازگاری است.
یادگیری عمیق زیر مجموعه ای تخصصی تر از یادگیری ماشین است و از شبکه های عصبی با لایه های زیاد استفاده می کند، که این طرح از مغز انسان الهام گرفته شده است. یادگیری عمیق برای شناسایی همبستگیهای غیرخطی و پیچیده طراحی شده است و به مجموعه داده های بزرگتر و قدرت محاسباتی بیشتری، نیاز دارد. نحوه عملکرد شبکه های یادگیری عمیق به گونه ای است که از محیط و اشتباهات گذشته یاد می گیرد و آن ها را نسبت به همتایان یادگیری ماشین مستقل تر می کند. دیپ لرنینگ یا همان یادگیری عمیق به سمت سیستم هوش مصنوعی پیچیده تر و شبیه به انسان حرکت می کند.
بهترین زبان برنامه نویسی برای یادگیری ماشین
عوامل زیادی هستند که انتخاب زبان برنامه نویسی برای یادگیری ماشین به آن ها وابسته است، مثل مشکل، الزامات سیستم وتخصص توسعه دهنده. حدود 700 زبان برنامه نویسی وجود دارد که تعدادی محدودی از آن ها میتوانند به دلیل انعطاف پذیری، داشتن کتابخانه قوی و پشتیبانی محبوبیت پیدا کرده اند. برای عمیق شدن در یادگیری ماشین، دانش برنامه نویسی به اهدافی که شما دارید، وابسته است. مثلا اگر می خواهید مهندس یادگیری ماشین شوید، باید درک درستی از مفاهیم اصلی زبان که در یادگیری ماشین استفاده می شود، داشته باشید.
زبانهایی مانند پایتون، R، جاوا و سی پلاس پلاس به دلیل پردازش دادههای قدرتمند و قابلیتهای آماری ترجیح داده میشوند. به طور خاص، پایتون به دلیل سادگی و اکوسیستم گسترده کتابخانه های علوم داده مانند TensorFlow، PyTorch و Scikit-learn به عنوان یک زبان محبوب در جامعه یادگیری ماشین ظاهر شده است.
دانش برنامهنویسی و مفاهیم اصلی زبانهای مانند پایتون، R و جاوا ضروری است. “بهترین” زبان برای یادگیری ماشین می تواند بسته به زمینه، داده های موجود و مشکل خاصی که می خواهیم حل کنیم متفاوت باشد. همان طور که به عنوان یک مهندس یادگیری ماشین در سفر خود عمیق تر می شویم، احتمالاً بهترین زبان برنامه نویسی را مطابق با نیازهایمان پیدا خواهیم کرد.
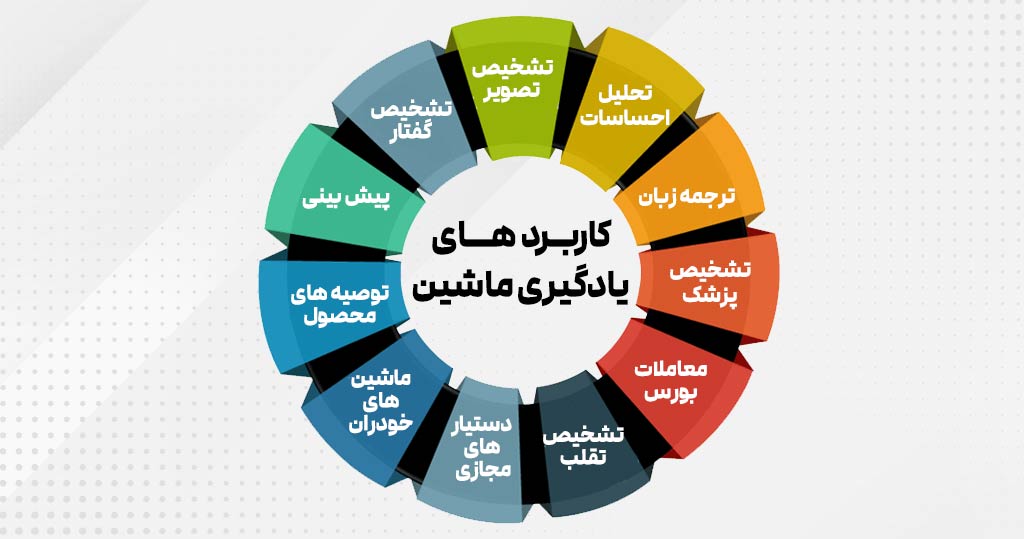
کاربردهای یادگیری ماشین
استفاده از ماشین لرنینگ برای حل مسائل زیادی در زمینههای مختلف به یک ضرورت تبدیل شده است، افزایش کلان داده ها (Big Data)، اینترنت اشیا و محاسبات فراگیر در اتفاق افتادن این جریان نیز نقش مهمی داشتند. در ادامه برخی از کاربردهای ماشین لرنینگ را بیان خواهیم کرد:
بینایی ماشین (computer vision)
بینایی ماشین مربوط به تشخیص چهره، ردیابی حرکت و تشخیص شی است و یکی از رایجترین کاربردهای یادگیری ماشین، در این زمینه است. از این قابلیت برای شناسایی اشیا، افراد، مکانها، تصاویر دیجیتال و … استفاده میکنیم. نمونه ای از کاربرد تشخیص تصویر را در فیس بوک دیده ایم. فیسبوک قابلیتی به نام Deep Face” وجود دارد که به کمک آن تشخیص چهره و شناسایی افراد داخل تصویر میسر می شود که فناوری پشت آن، الگوریتم تشخیص چهره یادگیری ماشین است.
پردازش زبان طبیعی
یکی از مثال هایی که در این زمینه می توان زد، تشخیص صدا است. یکی دیگر از کابردهای یادگیری ماشین، تشخیص گفتار است که فرآیندی است برای برای تبدیل دستورالعملهای صوتی به متن، و همچنین به عنوان «گفتار به متن» یا «تشخیص گفتار رایانهای». به کمک تشخیص گفتار میتوان کلمات موجود در یک فایل صوتی را به یک فایل متنی تبدیل کرد. در حال حاضر از این قابلیت یادگیری ماشین در برنامه های مختلفی استفاده می شود. دستیار گوگل، سیری، کورتانا و الکسا از فناوری تشخیص گفتار برای پیروی از دستورالعملهای صوتی استفاده میکنند.
پیش بینی
یکی از برجسته ترین کاربردهای یادگیری ماشین، آنالیز پیش بینی است. با تجزیه و تحلیل داده های تاریخی و شناسایی الگوها، الگوریتم های ماشین لرنینگ می توانند پیش بینی های دقیقی در مورد نتایج آینده داشته باشند.
این قابلیت در حوزه های متعددی مانند پیش بینی ترافیک، بازارهای مالی، پیش بینی آب و هوا، پیش بینی فروش و برنامه ریزی تقاضا کاربرد دارد.سازمانها میتوانند از تجزیه و تحلیل پیشبینیکننده برای بهینهسازی تصمیمگیری، کاهش ریسکها و کسب مزیت رقابتی در صنایع مربوطه استفاده کنند.
یادگیری ماشین یک فضای رقابتی برای سازمانها ایجاد میکند. برای مثال، استفاده از برنامههایی، مانند گوگل مپ یا سایر برنامه های مکان یابی، نمونه ای از این کاربرد هستند. هر زمان که بخواهیم از یک مکان جدید بازدید کنیم، از گوگل مپ کمک میگیریم و این برنامه کوتاه ترین مسیر با کمترین ترافیک را به ما نشان می دهد و هم چنین شرایط ترافیکی را هم پیش بینی می کند. این برنامه اطلاعات را از کاربر می گیرد و برای بهبود خود از آن ها استفاده می کند.
توصیه های محصول
یکی از محبوب ترین و شناخته شده ترین کاربردهای یادگیری ماشین، توصیه محصول است که اکثر وب سایت های تجارت الکترونیکی از این ویژگی استفاده می کنند. با استفاده از یادگیری ماشین و هوش مصنوعی، رفتار کاربر بر اساس خریدهای قبلی و الگوهای سرچ ردیابی و محصولات جدید به آن ها توصیه می شود.
گوگل از الگوریتم های مختلف یادگیری ماشین برای شناسایی و درک علاقه کاربر استفاده می کند تا محصول را بر اساس علاقه مندی هایش به او پیشنهاد داد. شرکت های مختلف تجارت الکترونیک و سرگرمی مانند آمازون، نتفلیکس و … هم از این الگوریتم برای پیشنهاد محصول به کاربر استفاده می کنند. مثلا هر زمان که به دنبال یک محصول در آمازون هستیم، موقع گشت و گذار در اینترنت همان مرورگر، تبلیغاتی از آن محصول را دریافت می کنیم و این به دلیل وجود الگوریتم های یادگیری ماشین است. نمونه دیگری از این کاربرد در سریال های سرگرمی و فیلم ها است که به کمک یادگیری ماشین انجام می شود.

ماشین های خودران
یادگیری ماشین نقش مهمی در توسعه وسایل نقلیه خودران دارد. الگوریتمهای ماشین لرنینگ دادههای حسگر را از دوربینها، LiDAR و سیستمهای رادار پردازش میکنند تا اشیا را شناسایی کنند، علائم جاده را تشخیص دهند و تصمیمگیری در زمان واقعی برای ناوبری و رانندگی ایمن بگیرند. تسلا برای تولید خودروهای خودران از روش یادگیری بدون نظارت برای آموزش به ماشین های خود برای تشخیص افراد و اشیا موقع رانندگی استفاده می کند.
فیلترکردن هرزنامه و بدافزار ایمیل
وقتی ایمیل جدیدی دریافت می کنیم یا در صندوق ورودی با لیبل مهم و عادی نمایش داده می شود یا در پوشه ایمیل های هرزنامه. فیلترینگ ایمیل از فناوری یادگیری ماشین استفاده می کند و برخی از فیلترهای هرزنامه استفاده توسط Gmail شامل موارد زیر است:
- فیلتر محتوا
- فیلتر سرصفحه
- فهرستهای سیاه عمومی
- فیلترهای مبتنی بر قوانین
- فیلترهای مجوز
- دستیار شخصی مجازی
دستیارهای مجازی
یادگیری ماشین به دستیارهای مجازی مانند سیری، الکسا و دستیار گوگل قدرت می دهد. این دستیارها از الگوریتمهای پردازش زبان طبیعی و یادگیری ماشین برای درک سؤالات کاربر، ارائه اطلاعات مرتبط و انجام کارهایی مانند تنظیم یادآوری، ارسال پیام یا پخش موسیقی استفاده میکنند.
گوگل، الکسا، کورتانا و سیری دستیارهای شخصی مجازی هستند که از آن ها برای یافتن اطلاعات با استفاده از آموزش صوتی استفاده می کنیم. یادگیری ماشین به این دستیارهای مجازی قدرت می دهد. دستیاران مجازی به روش های مختلفی مانند پردازش زبان طبیعی برای درک سوالات کاربر، ، ارائه اطلاعات مرتبط و انجام کارهایی مانند تنظیم یادآوری، ارسال پیام یا پخش موسیقی به ما کمک می کنند.
تشخیص تقلب
الگوریتم های یادگیری ماشین برای تشخیص فعالیت های تقلبی در زمان واقعی موثر هستند. آن ها می توانند الگوها، ناهنجاری ها و رفتار کاربر را برای شناسایی تهدیدات بالقوه و نقض امنیت تجزیه و تحلیل کنند. مدل های یادگیری ماشین برای جلوگیری از کلاهبرداری کارت اعتباری، شناسایی نفوذهای شبکه و محافظت از دادههای حساس کاربرد دارند.
برای شناسایی تراکنش واقعی و تراکنش تقلبی، یادگیری ماشین به ما کمک می کند. روش های مختلفی برای انجام یک تراکنش تقلبی وجود دارد، مانند مانند حسابهای جعلی، شناسههای جعلی، و سرقت پول در وسط تراکنش که یادگیری با استفاده از شبکه عصبی فید فوروارد به تشخیص تراکنش واقعی کمک می کند. از آن جایی که برای هر تراکنش واقعی یک الگوی خاص وجود دارد، در صورتی که واکنش تقلبی صورت گیرد، این الگو تغییر پیدا کرده و نوع واکنش شناسایی می شود. این مدل، تراکنش های آنلاین را ایمن تر می کند.
معاملات بورس
از آن جایی که بازار سهام همیشه در نوسان است و بسیار بالا و پایین می شود، از یادگیری ماشین به طور گسترده در این حوزه استفاده می شود. در این زمینه از شبکه های عصبی با حافظه کوتاه مدت برای پیش بینی روند بازار سهام استفاده می شود.

تشخیص پزشکی
یکی از کاربرهای یادگیری ماشین در علم پزشکی، تشخیص بیماری ها است. یادگیری ماشین با کمک به تشخیص بیماریها، پیشبینی نتایج بیمار و توسعه برنامههای درمانی شخصی، مراقبتهای بهداشتی را متحول میکند. مدلهای یادگیری ماشین میتوانند تصاویر پزشکی، سوابق بیمار و دادههای ژنتیکی را برای کمک به تشخیص زودهنگام، ارزیابی خطر و پزشکی دقیق تجزیه و تحلیل کنند. در کل، به کمک ماشین لرنینگ، صنعت پزشکی در حال رشد و پیشرفت است و می تواند مدل های سه بعدی را بسازد که توانایی پیش بینی موقعیت دقیق ضایعات را در مغز، دارد. هم چنین برای یافتن تومورهای مغزی و سایر بیماری های مرتبط با مغز هم از این ویژگی استفاده می شود.

ترجمه زبان
یادگیری ماشین نقش مهمی برای ترجمه زبان به زبان های دیگر دارد و یکی از رایج ترین برنامه های یادگیری ماشین است. برای تبدیل متن یا زبان به سایر زبان های شناخته شده که با آن ها آشنا نیستیم، می توانیم از گوگل ترنسلیت استفاده کنیم. GNMT( Google Neural Machine Translation) یک یادگیری ماشین عصبی است که می تواند متن را به طور خودکار ترجمه کند و به ما کمک می کند تا بتوانیم با افراد دیگر از سراسر جهان ارتباط برقرار کنیم.
آنالیز رسانه های اجتماعی ( سوشال مدیا)
الگوریتم های یادگیری ماشین داده های رسانه های اجتماعی را تجزیه و تحلیل می کنند تا بینشی در مورد رفتار کاربر، تجزیه و تحلیل احساسات و پیش بینی روند به دست آورند. این به کسبوکارها کمک میکند ترجیحات مشتری را درک کنند، کمپینهای بازاریابی را هدف قرار دهند و تعامل با مشتری را بهبود بخشند.
از الگوریتم و رویکرد یادگیری ماشین برای ایجاد ویژگی های جذاب و عالی در این برنامه ها استفاده می شود. مثلا فیس بوک، تمامی فعالیت ها، چت ها، لایک ها، نظرات و حتی زمانی که در آن صرف می کنیم را ثبت و ضبط می کند. یادگیری ماشین بر اساس تجربه و رفتار شما، پیشنهاداتی را به شما ارائه می دهد.
یادگیری ماشین با ثبت و ضبط تمام فعالیتها و رفتارها در برنامههایی مانند فیس بوک، بر اساس تجربه و رفتار کاربران، پیشنهادات جذاب و عالی ارائه میدهد.
یادگیری ماشین بر اساس تجربه و رفتار کاربران، پیشنهادات جذاب ارائه میدهد. یکی دیگر از کاربردهای ماشین لرنینگ در پلتفرم شبکه های اجتماعی بوده از از ماشین لرنینگ برای بهبود منافع خود و کاربران استفاده می کنند تا بتوانند تبلیغات هدفمند تری داشته باشند. در ادامه چند نمونه معرفی می کنیم که حتما به آن برخورد کرده بودید و از آن استفاده می کردید بدون آنکه متوجه شوید، این ها جزو ویژگی های فوق العاده ماشین لرنینگ هستند.
معرفی افراد به شما: نحوه کار یادگیری ماشین به این گونه است که بر اساس درک تجربیات کار می کند. فیس بوک تمامی رفتارهای شما را زیر نظر می گیرد، مثلا با چه افرادی بیشتر تعامل دارید، از چه پروفایل هایی بازدید می کنید، علایق شما چیست و چه مطالبی را به اشتراک می گذارید و غیره. بر اساس این تجربیات یاد می گیرد که چه افرادی را به شما پیشنهاد دهد که بتوانید با آن ها ارتباط داشته باشید.
تحلیل احساسات
الگوریتمهای یادگیری ماشین میتوانند دادههای متنی از رسانههای اجتماعی، بررسیهای مشتریان و نظرسنجیها را برای تعیین احساسات و استخراج بینش تجزیه و تحلیل کنند. تحلیل احساسات توسط کسبوکارها برای درک بازخورد مشتری، نظارت بر شهرت برند و تصمیمگیری مبتنی بر دادهها برای بازاریابی و توسعه محصول استفاده میشود.
مدیریت انرژی
یادگیری ماشین در سیستمهای انرژی برای بهینهسازی مصرف انرژی، پیشبینی تقاضای انرژی و بهبود بهره وری انرژی استفاده میشود. مدلهای ML میتوانند دادههای شبکههای هوشمند، حسگرها و الگوهای آب و هوا را برای بهینهسازی توزیع انرژی، کاهش اتلاف و ترویج شیوههای انرژی پایدار تجزیه و تحلیل کنند.
پیش بینی ریزش مشتری
مدلهای یادگیری ماشین میتوانند دادههای مشتری را برای پیشبینی ریزش یا فرسایش مشتری تجزیه و تحلیل کنند. با شناسایی الگوها و شاخص های ریزش، کسب و کارها می توانند اقدامات پیشگیرانه ای برای حفظ مشتریان، بهبود رضایت مشتری و افزایش وفاداری مشتری انجام دهند.
کنترل کیفیت و تشخیص ناهنجاری
یادگیری ماشین را می توان برای نظارت و تشخیص ناهنجاری ها یا تشخیص عیوب در فرآیندهای تولید به کار برد. مدلهای ماشین لرنینگ میتوانند دادههای حسگر، دادههای خط تولید و سوابق تاریخی را برای شناسایی انحرافات از الگوهای مورد انتظار تجزیه و تحلیل کنند و با مداخله به موقع، موجب بهبود کنترل کیفیت شوند.
این مثالها کاربردهای متنوع یادگیری ماشین
را در حوزههای مختلف نشان میدهند و پتانسیل آن را برای هدایت نوآوری و بهبود کارایی در صنایع مختلف نشان میدهند.
محاسبات مالی
این حوزه به مسائلی مانند رتبه بندی اعتبار و معاملات الگوریتمی اشاره دارد و از ماشین لرنینگ در این حوزه استفاده می شود.

مزایا و معایب یادگیری ماشین
مزایا:
شناسایی روندها و الگوها در کمترین زمان ممکن
الگوریتم های یادگیری ماشین می توانند حجم زیادی از داده ها را به سرعت و با دقت تجزیه و تحلیل کنند که منجر به بهبود تصمیم گیری و کارایی در کارهای مختلف می شود.
اتوماسیون و صرفه جویی در زمان
با یادگیری ماشین بسیاری از کارهای تکراری اتوماتیک وار انجام می شود و این کار در زمان صرفه جویی می کند. سازمان ها به کمک این ویژگی می توانند برای انجام فعالیت های با ارزش تر تمرکز کنند. به کمک این ویژگی ها ماشین ها می توانند پیش بینی کنند و الگوریتم هایشان را بهبود دهند
مدیریت دادههای پیچیده
الگوریتم های یادگیری ماشین میتواند دادههای پیچیده و چند بعدی را مدیریت کند، از جمله دادههای ساختاریافته و بدون ساختار، متن، تصاویر و ویدئوها، استخراج بینشها و الگوهای ارزشمندی که ممکن است برای الگوریتمهای سنتی چالش برانگیز باشد. این الگوریتم ها می توانند این کار را در محیط های پویا و نامشخص انجام دهند.
شخصیسازی و توصیهها
به کمک یادگیری ماشین، سیستم های توصیه ای تقویت می شوند و تجربیات کار مطابق با ترجیحات و رفتارش شخصی سازی می شود. این کار باعث بهبود رضایت و تعامل مشتری می شود.
یادگیری مستمر و سازگاری
مدلهای یادگیری ماشین میتوانند از دادههای جدید یاد بگیرند و پیشبینیها یا رفتار خود را در طول زمان تطبیق دهند. این به سیستم اجازه می دهد تا با دریافت داده های بیشتر، عملکرد و دقت خود را بهبود بخشد.
معایب:
یادگیری ماشین علاوه بر مزایا و ویژگی ها، یکسری معایب هم دارد که در ادامه آن ها را معرفی می کنیم:
وابستگی به داده ها
مدل های یادگیری ماشین به داده های آموزشی وابسته هستند. داده های ناکافی می توانند موجب پیش بینی های نادرست، تقویت سوگیری یا اتخاذ تصمیم های نادرست شوند.
تفسیر نتایج و پیچیدگی
مدلهای یادگیری ماشین، بهویژه مدلهای یادگیری عمیق، میتوانند پیچیده و تفسیر آن ها دشوار باشد. درک فرآیند تصمیم گیری این مدل ها چالش برانگیز است و توضیح یا توجیح نتایج را دشوارتر می کند.
منابع محاسباتی
الگوریتم های یادگیری ماشین از نظر محاسباتی پیچیده هستند و برای اجرا به منابع زیادی نیاز دارند. آموزش این الگوریتم ها گران است و نیاز به سرمایه گذاری در سخت افزار و نرم افزار دارد.
زمان
آموزش الگوریتم یادگیری ماشین فرآیندی زمان بر است و با توجه به پیچیدگی مشکل و مقدار داده های موجود، آموزش ممکن است چندین روز طول بکشد.
احتمال خطای زیاد
در ماشین لرنینگ، الگوریتم ها بر اساس نتایج دقیق انتخاب می شوند. به همین دلیل لازم است نتایج را روی هر الگوریتم اجرا کنیم. از آن جایی که داده های زیادی وجود دارد، ممکن است حذف خطاها غیر ممکن شود. هم چنین رفع خطاها مدت زمان زیادی هم نیاز دارد.
آینده یادگیری ماشین چگونه خواهد بود؟
به کمک ماشین لرنینگ می توان حجم زیادی از داده ها را تجزیه و تحلیل کرد. استفاده از ماشین لرنینگ فقط محدود به زمان حال نمی شود و ما پیش تر، بدون این که بدانیم از ماشین لرنینگ در جاهای مختلف استفاده کردیم. شرکت های بزرگ برای بهبود منافع خود و بهبود ارتباط با مشتریان همواره از ماشین لرنینگ استفاده کردند. علاوه بر این ماشین لرنینگ در صنایع و کسب و کارهای مختلفی استفاده می شود و تاثیرات زیادی بر روی تصمیم گیری ها و پردازش داده ها دارد.
در سال های اخیر شاهد پیشرفت های زیادی در این زمینه بودیم، طوری که پیش بینی می شود در آینده ای نه چندان دور، حجم زیادی داده جمع آوری خواهد شد و این نقطه عطفی است برای تولید خودکار مدل های پیشرفته و افزایش اهمیت یادگیری ماشین. بنابراین می توان گفت که این علم سبب به وجود آمدن اتفاقات جذاب و جالبی خواهد شد. به عنوان سخن آخر منتظر اتفاقاتی باشید که در فیلم نامه های تخیلی هم هنوز به آن اشاره نشده اما قرار است در زندگی واقعی شاهد آن اتفاقات باشیم و این امر با پیشرفت هوش مصنوعی و یادگیری ماشین میسر می شود.