
شرکت فرانسوی Mistral این بار وارد دنیای صدا شده و از اولین مدل صوتی خود با نام Voxtral رونمایی کرده است. این مدل بهصورت کاملا متنباز منتشر شده و میتواند تبدیل صدا به متن را با دقت بالا انجام دهد.
براساس گزارش TechCrunch، مدل Voxtral این مزیتها را دارد: کاملا متنباز است، آموزش مستقل و دسترسی آزاد برای همهی کاربران دارد. میسترال این مدل را بر پایهی همان معماری Whisper طراحی کرده، اما از صفر آن را خودش آموزش داده است.
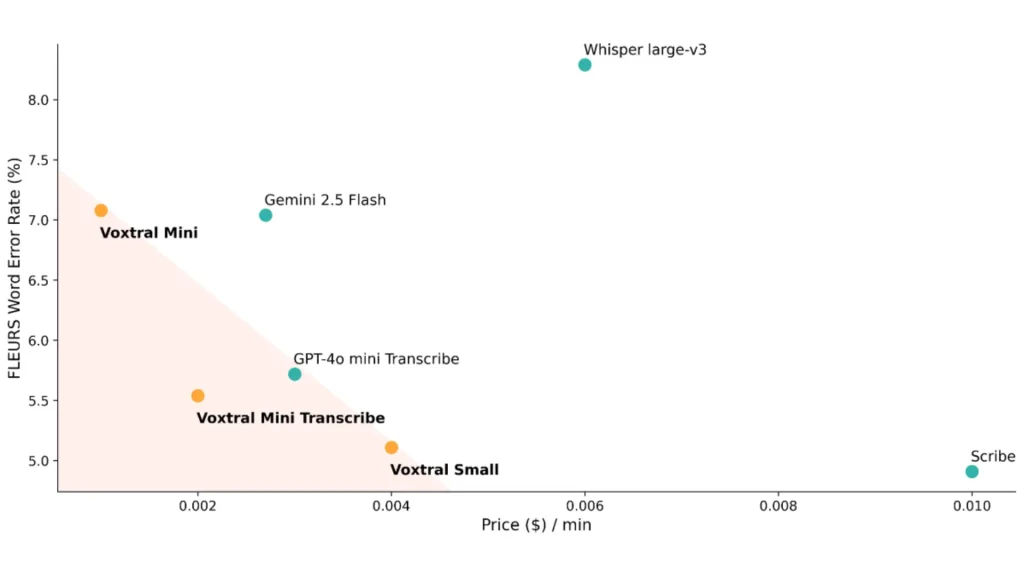
مدل Voxtral چه ویژگیهایی دارد؟
- تبدیل صدا به متن (Speech-to-Text) با دقت بالا
- متنباز و رایگان برای استفاده تجاری یا پژوهشی
- قابل اجرا روی سیستمهایی با منابع محدود
- پشتیبانی از چند زبان (جزئیات زبانها هنوز مشخص نیست، اما انگلیسی تأیید شده)
میسترال با این مدل نشان داد که نمیخواهد فقط به مدلهای متنی محدود بماند و در حوزههای دیگر مانند هوش مصنوعی صوتی نیز حرفی برای گفتن داشته باشد. درست همانطور که گوگل با ابزار NotebookLM سعی دارد متون را هوشمندانه خلاصه و سازماندهی کند. در خبر قابلیت «دفترچهی ویژه» در NotebookLM به این موضوع پرداختهایم.