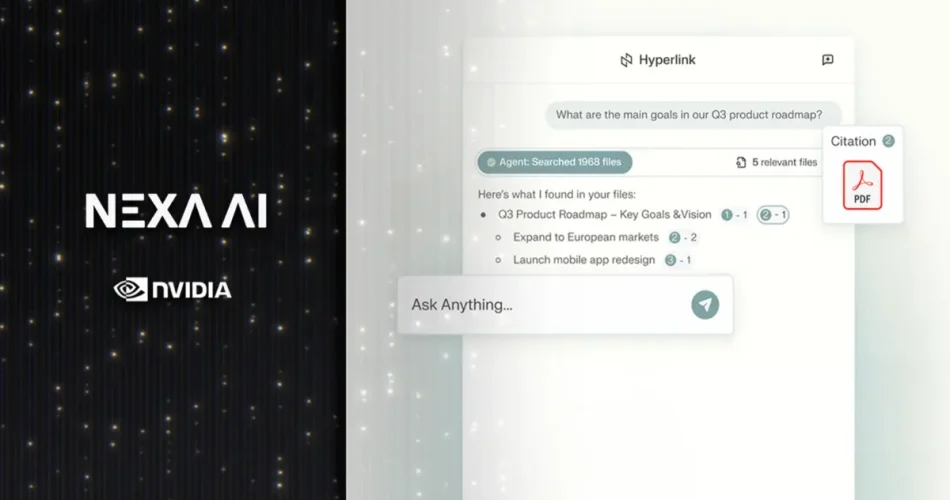
انویدیا نسخهی جدید نرمافزاری با نام Hyperlink را معرفی کرده است که به کاربران امکان میدهد تمام فایلهای خود اعم از تصاویر، اسلایدها، پیدیافها، اسناد و متنها را با سرعت بالا و بهصورت توصیفی جستوجو، دستهبندی و میان آنها ارتباط برقرار کنند.

جدیدترین اخبار تکنولوژی هوش مصنوعی و شبکههای اجتماعی را در نامبرلند بخوانید.
بهگفتهی انویدیا، Hyperlink که توسط استارتاپ Nexa AI (زیر مجموعهی انویدیا) توسعه یافته است، یک دستیار هوش مصنوعی محلی برای سازماندهی به اطلاعات حجیم محسوب میشود. این نرمافزار برای کامپیوترهایی با معماری RTX AI بهینه شده است و در بررسیهای انجامشده، بنچمارکهای بهتری در این سیستمها ارائه میدهد.
هایپرلینک بهصورت محلی روی کامپیوتر کاربر اجرا میشود و برخلاف خدمات مبتنیبر پردازش ابری، نیازی به ارسال دادهها به سرورهای خارجی ندارد. بدین ترتیب، امنیت اطلاعات شخصی یا محرمانه بهتر تضمین میشود.
انویدیا میگوید مدلهای زبانی بزرگ براساس حجم گستردهای از اطلاعات آموزش دیدهاند، اما نمیتوانند به اطلاعاتی که در میان انبوهی از فایلهای مختلف در کامپیوتر شخصی افراد پراکنده شدهاند دسترسی داشته باشند. نرمافزار هایپرلینک برای پاسخ به همین مشکل ساخته شده است.
یکی از نقاط تمایز نسخهی جدید هایپرلینک، فهم معنای محتوا است. Hyperlink نهتنها بر اساس نام فایلها جستجو میکند، بلکه متن درون آنها را بررسی و با درک هدف کاربر، موارد مرتبط را استخراج میکند. بنابراین حتی اگر فایلها عنوانی قابل جستوجو نداشته باشند، این نرمافزار میتواند آنها را شناسایی کند.
هایپرلینک از فرایندی تحت عنوان تولید تقویتشدهی بازگشتی (RAG) بهره میبرد. RAG روشی در هوش مصنوعی است که در آن مدل زبانی هنگام تولید پاسخ، فقط به اطلاعات درونی خودش تکیه نمیکند؛ بلکه ابتدا از یک سیستم جستوجوی داخلی کمک میگیرد تا اسناد یا دادههای مرتبط را میان فایلها بازیابی کند و سپس با ترکیب آن اطلاعات، پاسخ دقیقتری بسازد.
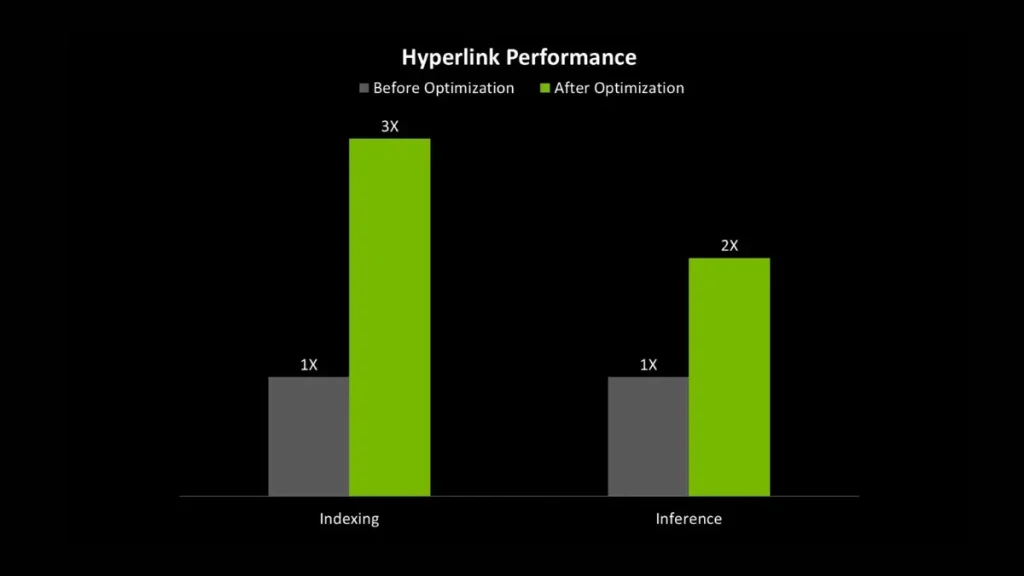
طبق آزمایشی که روی یک سیستم مجهزبه کارت گرافیک RTX 5090 صورت گرفت، مشخص شد که نرمافزار هایپرلینک در شاخص سرعت فهرستبندی (Indexing) تا سه برابر و در شاخص سرعت استنتاج مدل زبانی (LLM Inference) تا دو برابر سریعتر بود. بهعنوان مثال، زمان Indexing یک فایل یک گیگابایتی از 15 دقیقه به پنج دقیقه کاهش یافته است.
سرعت indexing به زمانی اشاره دارد که یک سیستم میتواند مجموعهای از فایلها را اسکن، تحلیل و در دیتابیس داخلی خود ثبت کند تا بعدها سریعتر قابل جستوجو باشند. هرچه این مرحله سریعتر انجام شود، کاربر زودتر میتواند از قابلیت جستوجوی هوشمند ابزار استفاده کند. سرعت LLM inference مربوط به زمانی است که مدل هوش مصنوعی میتواند ورودی کاربر را پردازش و پاسخ تولید کند.
انویدیا میگوید که هایپرلینک قابلیت ارتباطدهی بین اسناد مختلف را دارد؛ میتواند مفاهیم پراکنده در اسلایدها، یادداشتها و تصاویر را به هم متصل کند و پاسخهایی ساختاریافته به کاربر ارائه دهد. این ویژگی برای مدیران، پژوهشگران و کسانی که با حجم بزرگ دادههای متنی کار میکنند، جذاب است.
اجرای محلی نرمافزار هایپرلینک معمولاً به سختافزار نسبتاً قدرتمندی بهویژه کارتهای گرافیک جدید سری RTX نیاز دارد. کاربران باید مطمئن شوند که فضای ذخیرهسازی و قدرت پردازش مناسبی در اختیار دارند.
با گسترش ابزارهای مبتنیبر هوش مصنوعی، نیاز به زیرساختهای این فناوری نیز بیشتر میشود. همین عامل موجب کمبود تراشههای رم در بازار لوازم الکترونیکی شده است.